

Benchmark
LLM instruction-following evaluation service
The service provides comprehensive evaluation and customized solutions for LLMs, offering model performance assessment, data strategy consultation, tailored dataset creation, and cost-effective iteration management.
LLM Benchmark Dataset Features
Model Target

Professional scene coverage
High Data Quality Standards

Evaluation-Algorithm Collaboration Iteration
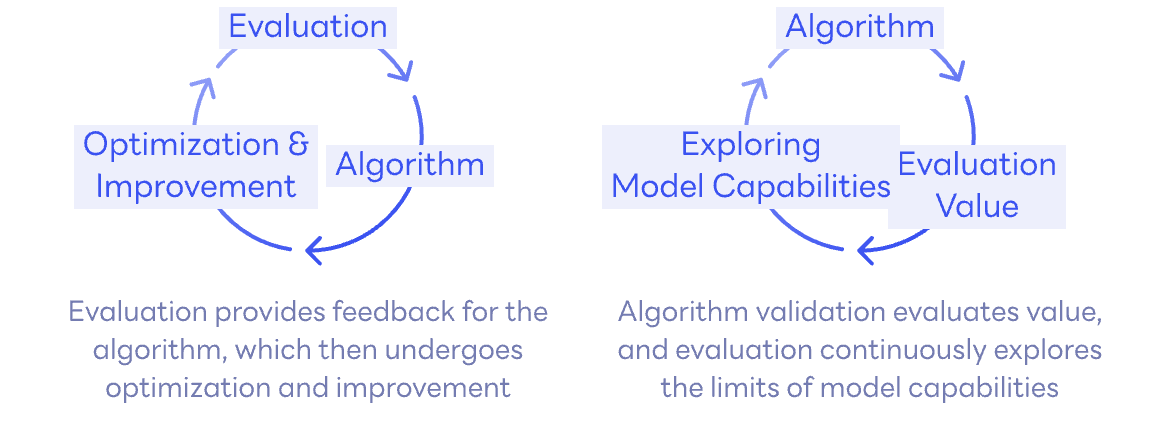
Benchmark with custom datasets
Data-strategy-centered service dedicated to ensuring top-notch quality throughout the planning and production phases.
1. Data Production Strategy
Standardize data content based on model objectives, ensuring both diversity and accuracy.
2. Incentive Mechanism
Implement an incentive mechanism for the data team, aligning tasks with specialized expertise to cover a wide range of data scenarios.

4. Data Analytics Report
Provide comprehensive statistical analysis of data distribution and corner case summaries to optimize the production process and uphold the highest data quality standards.
3. Data Strategy Training
Collaborate with the data team to refine production processes and deepen data understanding.
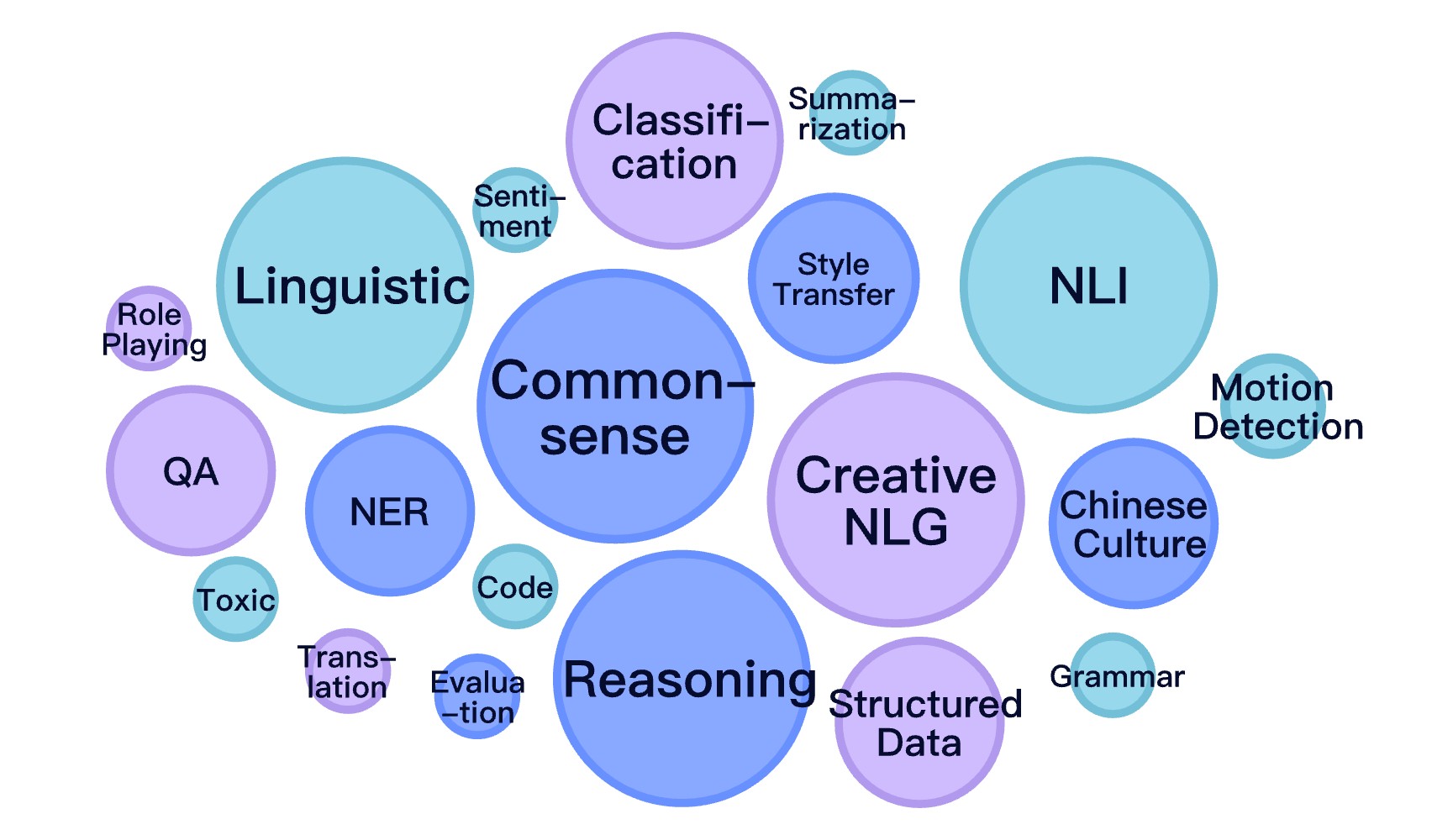
CIF-Bench
The first LLM instruction-following evaluation services in the world.
Evaluation system
20
Dimensions
150
Tasks
15000
Evaluation Data Points
4
Metrics Framework
Automated Evaluation Ranking
The evaluation of 28 selected LLMs models revealed significant performance gaps, highlighting the limitations of LLMs' generalization capabilities in Chinese task environments.
| Baichuan2-13B-Chat | 0.529 | 0.52 | 0.674 | 0.333 | 0.641 | 0.497 | 0.686 | 0.542 | 0.528 | 0.578 | 0.563 | 0.632 | 0.569 | 0.515 | 0.752 | 0.624 | 0.459 | 0.462 | 0.332 | 0.441 | 0.273 |
| Qwen-72B-Chat | 0.519 | 0.486 | 0.63 | 0.296 | 0.634 | 0.508 | 0.634 | 0.458 | 0.52 | 0.494 | 0.55 | 0.626 | 0.565 | 0.528 | 0.762 | 0.613 | 0.496 | 0.459 | 0.282 | 0.608 | 0.271 |
| Yi-34B-Chat | 0.512 | 0.483 | 0.606 | 0.347 | 0.623 | 0.497 | 0.598 | 0.48 | 0.49 | 0.575 | 0.525 | 0.619 | 0.554 | 0.494 | 0.757 | 0.58 | 0.472 | 0.439 | 0.346 | 0.514 | 0.259 |
| Qwen-14B-Chat | 0.5 | 0.481 | 0.582 | 0.307 | 0.614 | 0.494 | 0.645 | 0.428 | 0.475 | 0.496 | 0.513 | 0.616 | 0.548 | 0.507 | 0.764 | 0.583 | 0.469 | 0.453 | 0.283 | 0.575 | 0.262 |
| Deepseek-Llm-67B-Chat | 0.471 | 0.467 | 0.571 | 0.259 | 0.577 | 0.486 | 0.549 | 0.442 | 0.476 | 0.475 | 0.509 | 0.566 | 0.496 | 0.439 | 0.711 | 0.546 | 0.409 | 0.436 | 0.262 | 0.57 | 0.235 |
| Baichuan-13B-Chat | 0.45 | 0.408 | 0.491 | 0.286 | 0.552 | 0.439 | 0.67 | 0.417 | 0.422 | 0.482 | 0.486 | 0.565 | 0.505 | 0.377 | 0.704 | 0.552 | 0.387 | 0.402 | 0.35 | 0.431 | 0.304 |
| Chatglm3-6B | 0.436 | 0.381 | 0.439 | 0.33 | 0.541 | 0.452 | 0.577 | 0.31 | 0.358 | 0.436 | 0.453 | 0.544 | 0.503 | 0.414 | 0.762 | 0.56 | 0.446 | 0.402 | 0.321 | 0.391 | 0.27 |
| Yi-6B-Chat | 0.417 | 0.402 | 0.454 | 0.313 | 0.523 | 0.425 | 0.506 | 0.383 | 0.383 | 0.487 | 0.396 | 0.523 | 0.457 | 0.369 | 0.754 | 0.482 | 0.401 | 0.38 | 0.31 | 0.455 | 0.227 |
| Baichuan2-7B-Chat | 0.412 | 0.437 | 0.647 | 0.16 | 0.52 | 0.402 | 0.58 | 0.511 | 0.444 | 0.455 | 0.407 | 0.489 | 0.395 | 0.406 | 0.67 | 0.517 | 0.342 | 0.298 | 0.101 | 0.463 | 0.138 |
| Chatglm2-6B | 0.352 | 0.278 | 0.469 | 0.346 | 0.403 | 0.424 | 0.535 | 0.274 | 0.397 | 0.406 | 0.24 | 0.397 | 0.352 | 0.326 | 0.714 | 0.438 | 0.298 | 0.313 | 0.32 | 0.461 | 0.19 |
| Chatglm-6B-Sft | 0.349 | 0.265 | 0.454 | 0.365 | 0.385 | 0.462 | 0.554 | 0.296 | 0.379 | 0.427 | 0.232 | 0.38 | 0.321 | 0.292 | 0.718 | 0.415 | 0.296 | 0.333 | 0.351 | 0.441 | 0.19 |
| Chinese-Llama2-Linly-13B | 0.344 | 0.25 | 0.462 | 0.311 | 0.399 | 0.429 | 0.557 | 0.273 | 0.358 | 0.385 | 0.268 | 0.39 | 0.33 | 0.313 | 0.653 | 0.433 | 0.279 | 0.332 | 0.292 | 0.457 | 0.181 |
| Gpt-3.5-Turbo-Sft | 0.343 | 0.269 | 0.427 | 0.298 | 0.389 | 0.395 | 0.575 | 0.325 | 0.365 | 0.389 | 0.226 | 0.382 | 0.394 | 0.345 | 0.71 | 0.433 | 0.324 | 0.266 | 0.29 | 0.397 | 0.225 |
| Chinese-Alpaca-2-13B | 0.341 | 0.242 | 0.421 | 0.356 | 0.382 | 0.442 | 0.602 | 0.256 | 0.363 | 0.43 | 0.21 | 0.376 | 0.334 | 0.317 | 0.714 | 0.459 | 0.299 | 0.316 | 0.308 | 0.452 | 0.2 |
| Chinese-Alpaca-13B | 0.334 | 0.25 | 0.399 | 0.348 | 0.364 | 0.435 | 0.616 | 0.275 | 0.349 | 0.421 | 0.223 | 0.37 | 0.309 | 0.319 | 0.724 | 0.426 | 0.285 | 0.307 | 0.298 | 0.445 | 0.181 |
| Chinese-Alpaca-7B | 0.334 | 0.216 | 0.412 | 0.378 | 0.381 | 0.425 | 0.576 | 0.265 | 0.359 | 0.393 | 0.243 | 0.383 | 0.326 | 0.295 | 0.71 | 0.409 | 0.301 | 0.327 | 0.325 | 0.405 | 0.186 |
| Chinese-Llama2-Linly-7B | 0.333 | 0.218 | 0.451 | 0.33 | 0.396 | 0.427 | 0.583 | 0.248 | 0.35 | 0.41 | 0.231 | 0.367 | 0.345 | 0.276 | 0.698 | 0.433 | 0.259 | 0.315 | 0.31 | 0.469 | 0.168 |
| Tigerbot-13B-Chat | 0.331 | 0.205 | 0.397 | 0.309 | 0.385 | 0.42 | 0.614 | 0.31 | 0.379 | 0.341 | 0.276 | 0.363 | 0.329 | 0.301 | 0.694 | 0.419 | 0.28 | 0.31 | 0.283 | 0.393 | 0.186 |
| Telechat-7B | 0.329 | 0.267 | 0.338 | 0.321 | 0.42 | 0.404 | 0.42 | 0.272 | 0.265 | 0.327 | 0.32 | 0.388 | 0.355 | 0.244 | 0.672 | 0.344 | 0.334 | 0.335 | 0.299 | 0.364 | 0.184 |
| Ziya-Llama-13B | 0.329 | 0.196 | 0.402 | 0.324 | 0.341 | 0.428 | 0.616 | 0.312 | 0.349 | 0.4 | 0.228 | 0.351 | 0.279 | 0.313 | 0.721 | 0.468 | 0.311 | 0.291 | 0.278 | 0.431 | 0.175 |
| Chinese-Alpaca-33B | 0.326 | 0.234 | 0.37 | 0.372 | 0.364 | 0.429 | 0.614 | 0.246 | 0.318 | 0.377 | 0.221 | 0.368 | 0.3 | 0.314 | 0.713 | 0.428 | 0.288 | 0.303 | 0.295 | 0.401 | 0.199 |
| Tigerbot-7B-Chat | 0.325 | 0.218 | 0.395 | 0.306 | 0.37 | 0.413 | 0.631 | 0.294 | 0.37 | 0.368 | 0.215 | 0.355 | 0.313 | 0.292 | 0.713 | 0.415 | 0.283 | 0.315 | 0.29 | 0.389 | 0.171 |
| Chinese-Alpaca-2-7B | 0.323 | 0.215 | 0.374 | 0.335 | 0.366 | 0.415 | 0.546 | 0.257 | 0.326 | 0.395 | 0.215 | 0.375 | 0.318 | 0.289 | 0.698 | 0.417 | 0.285 | 0.303 | 0.312 | 0.439 | 0.193 |
| Aquilachat-7B | 0.309 | 0.162 | 0.234 | 0.291 | 0.32 | 0.437 | 0.344 | 0.135 | 0.266 | 0.309 | 0.287 | 0.337 | 0.342 | 0.236 | 0.609 | 0.255 | 0.249 | 0.4 | 0.527 | 0.43 | 0.306 |
| Moss-Moon-003-Sft | 0.302 | 0.214 | 0.405 | 0.274 | 0.347 | 0.38 | 0.448 | 0.305 | 0.341 | 0.378 | 0.232 | 0.317 | 0.321 | 0.267 | 0.694 | 0.375 | 0.251 | 0.259 | 0.288 | 0.424 | 0.152 |
| Qwen-7B-Chat | 0.301 | 0.211 | 0.41 | 0.289 | 0.349 | 0.391 | 0.531 | 0.219 | 0.387 | 0.404 | 0.208 | 0.325 | 0.297 | 0.278 | 0.681 | 0.419 | 0.266 | 0.251 | 0.248 | 0.371 | 0.157 |
| Belle-13B-Sft | 0.264 | 0.198 | 0.307 | 0.285 | 0.316 | 0.349 | 0.409 | 0.237 | 0.305 | 0.222 | 0.177 | 0.317 | 0.284 | 0.242 | 0.631 | 0.299 | 0.244 | 0.222 | 0.234 | 0.296 | 0.133 |
| Cpm-Bee-10B | 0.244 | 0.234 | 0.377 | 0.024 | 0.278 | 0.311 | 0.255 | 0.302 | 0.278 | 0.327 | 0.148 | 0.286 | 0.224 | 0.147 | 0.603 | 0.277 | 0.117 | 0.263 | 0.22 | 0.352 | 0.125 |
CIF-Bench Evaluation Service
We provide highly customizable evaluation services that seamlessly integrate with API or model code.
Unlimited Access to CIF-Bench Public Dataset
Including 45,000 data instances, the Chinese Instruction-Following Benchmark (CIF-Bench) enables the development of more adaptable, culturally aware, and linguistically diverse language models.
Automated Evaluation Service
By providing the API or model code, users can quickly and easily receive performance feedback on their models using our comprehensive dataset for model inference evaluation.
Manual Evaluation Service
Leveraging user-submitted interfaces, models, and code, our expert team conducts detailed tests to deliver a comprehensive report for you.
Explore More
Fill out the form to schedule a personalized demo with our team. Experience firsthand how our innovative solutions can meet your needs and drive success.
Copyright © 2025 StardustAI Inc. All rights reserved.